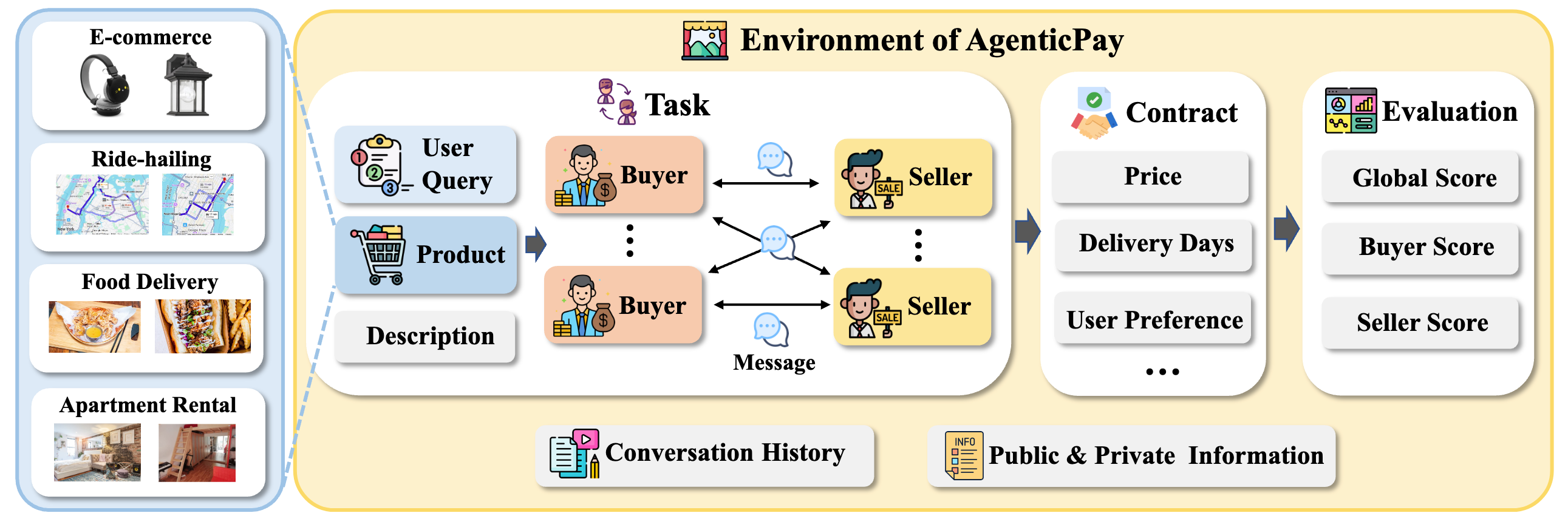
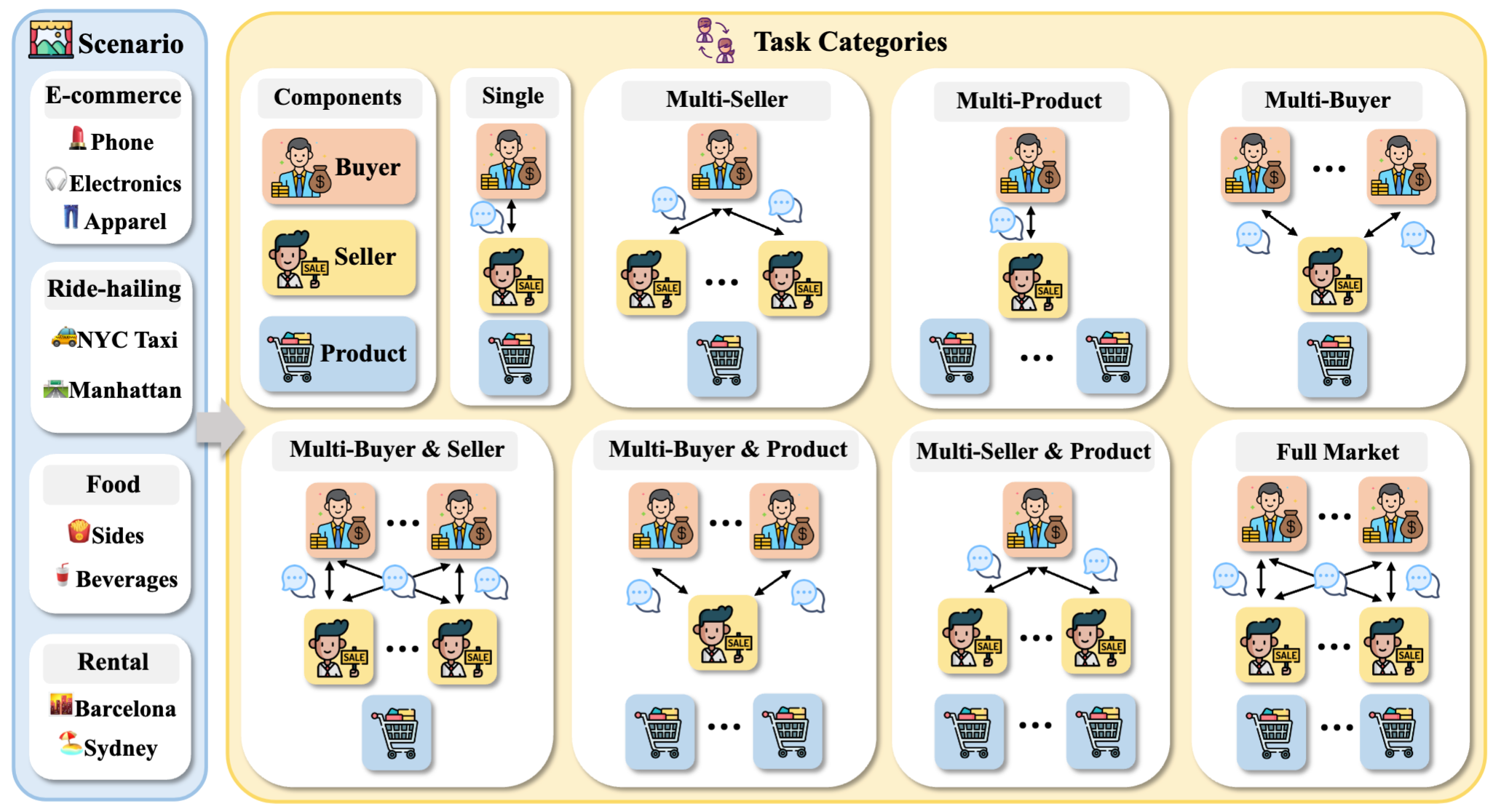
Agents based on large language models are increasingly expected to autonomously handle negotiation and transactions. However, existing benchmarks predominantly focus on text-only, bilateral, zero-sum price haggling, failing to capture the complexity of real-world commerce. To address this gap, we introduce AgenticPay, a unified framework and benchmark for evaluating how well multimodal agents reach high-welfare, multi-dimensional agreements in realistic markets. Built around four core components (Environments, Tasks, Agents, and Metrics), AgenticPay comprises 160 multimodal tasks spanning 4 real-world business scenarios (E-commerce, Food Delivery, Ride-hailing, and Apartment Rental) and 8 market topologies, scaling from 1-to-1 bargaining to many-to-many (N-to-N) competitive markets.
Beyond price haggling, agents must read product images, infer each opponent's hidden preferences, and trade off multiple binding contract terms (e.g., price, lease duration, return policy, delivery speed). Agents communicate through multi-round natural-language dialogue, with each turn proposing or revising a full contract, and outcomes are scored by a utility-based framework that rewards agreements maximizing joint welfare. Evaluations on state-of-the-art proprietary (GPT-5.4, Claude Sonnet 4.6, Gemini 3.1 Pro Preview) and open-weight (Qwen3-VL-32B-Instruct, InternVL3-38B) multimodal models reveal substantial gaps in non-zero-sum value creation and market reasoning: even the strongest agent (Gemini 3.1 Pro Preview) reaches a GlobalScore of only 42.3/100, and performance consistently degrades as markets scale from bilateral to multi-sided, with the average GlobalScore dropping by 5.7 points and open-weight models suffering the largest declines (up to 11.5 points). These findings establish AgenticPay as a foundational testbed for multimodal agentic commerce.